MSBD 6000H Natural Language Processing, BDT, HKUST
Group Project
Finish on May 22, 2020: Project Report PDF
Group Member: Fan Jiahao, Song Huancheng, YANG Rongfeng, Li Yuan, Tang Huimin
In the 21st century, socializing has become an integral part of human life. People socialize to obtain a variety of information and increase their sense of social identity. After the emergence of artificial intelligence, people hope to be able to communicate with machines in natural language, obtain information or help, and therefore generate the dialogue system. The birth of the dialogue system has brought more products such as Xiaodu, Xiaoai speakers, Siri, etc., which has brought great convenience to human life. In this project, in order to gain a deeper understanding of the principles and performance of the dialog system, we used two models to train on the dialog data set and used variety of evaluation methods to compare the performance to achieve the purpose of learning.
Introduction
In this part, let us firstly introduce our project to give an overview. The introduction part would be divided into two parts, respectively talking about the objective of project and the dataset we use.
Project Introduction
Nowadays, with the continuous advancement and development of technology, people start to put forward new requirements for machines, even including the social performance of them. Specifically, humans want to use natural language to talk or chat with machines, so the dialogue system came into being.
We are very interested in dialogue systems and want to understand how they are trained and run. Hence we specifically used two models: Some classic models like seq2seq and transformer, and Plato model (from Baidu) as well to train our data set (DailyDialog), observed and compared the final performance to achieve our purpose of learning. We would like to introduce our dataset and models in the following parts to give readers an overview.
Dataset Introduction
In this project, the DailyDialog dataset had been decided to be used in model training. DailyDialog dataset is a very famous dataset in the field of dialogue system, which is a multi-turn conversation dataset for daily chat scenarios. As we know, many of the existing dialogue datasets are not derived from real conversations. For example, some mainstream ones include post-reply pairs from social networks such as Weibo and Twitter, and some from movie lines. However, the former is often mixed with a lot of informal abbreviations and ‘network language’. On the other hand, there is also the problem of incomplete information. In addition, the lines in the movies are often too short, and the number of lines is too large, resulting in insufficient model training.
In order to find a better dialogue model that can serve daily communication, the author constructed the DailyDialog data set by crawling the spoken English conversation website. Because it is a dialogue in daily life, the dialogue covers a lot of emotional information, therefore there are many more natural dialogues patterns. Some examples are shown in Figure 1 to make sense:

This example is the first conversation in our training dataset, we could find that the purple underlined words have a more obvious emotional tendency. It can be seen that in the dialogue, person A wanted to have some beer at first, and then there are some changes (A chose another activity which is better for heath rather than beer) under person B’s enlightenment. It can also be seen from B’s words that B can actively provide A with some suggestions. And these suggestions often cover new information, which is also a way of expressing interaction in our daily conversations. Here Figure 2 is the basic statistics of DailyDialog dataset which is shown below.

From the two figures above (Figure 1 and Figure 2), we could conclude two advantages of DailyDialog dataset for our project:
- Judging from the magnitude of the dataset, both the number of turns and the length of each paragraph are sufficient. More effective data, avoiding noise, will greatly improve our training performance;
- DailyDialog concerns more on chit-chat, the dialogues it chooses are more suitable for human daily life rather than other datasets. So we could say that it is a good choice of using DailyDialog in our project.
Classic Model
Sequence-to-Sequence
Sequence to sequence has now become an important model in the fields of Machine translation, Dialogue chat, Text summary, etc.
The first article to propose sequence-to-sequence model (or Seq2Seq) was, but in @cho2014learning, the Seq2Seq model was the first used to solve the Machine Translation problem. In this paper, the author proposed a neural network model called RNN Encoder–Decoder that consists of two recurrent neural networks (RNN). Figure 3 is a general illustration of such structure.

However, generating responses was found to be considerably more difficult than translating between languages. It is likely due to the wide range of plausible responses and the lack of phrase alignment between the post and the response.
In dialogue system, a Seq2Seq model is also in an encoder-decoder structure. Given a source sequence (message) $X = (x_1, x_2, \cdots, x_T )$ consisting of $T$ words and a target sequence (response) $Y =(y_1, y_2, \cdots, y_T)$ of length $T$, the model maximizes the generation probability of $Y$ conditioned on $X$: $p(y_1, \cdots, y_T|x_1, \cdots, x_T )$.
The encoder reads $X$ word by word and represents it as a context vector $c$ through a recurrent neural network (RNN),and then the decoder estimates the generation probability of $Y$ with $c$ as the input. The encoder RNN calculates the context vector $c$ by:
$$h_t = f(x_t,h_t-1)$$
where $h_t$ is the hidden state at time step $t$, $f$ is a non-linear function such as long-short term memory unit (LSTM) and gated recurrent unit (GRU), and $c$ is the hidden state corresponding to the last word $h_T$ .
The decoder is a standard RNN language model with an additional conditional context vector $c$. The probability distribution $p_t$ of candidate words at every time $t$ is calculated as
$$S_t = f(y_t-1,S_t-1,C)$$
$$P_t = softmax(s_t,y_t-1)$$
where st is the hidden state of the decoder RNN at time $t$ and $y_{t_1}$ is the word at time $t_1$ in the response sequence. The objective function of Seq2Seq is defined as:
$$p(y_1,...,y_T|x_1,...,x_T)=p(y_1|c)\prod_{t=2}^Tp(y_t|c,y_1,...,y_t-1)$$
The previous model is to encode the source sequence into a vector of fixed dimensions, but doing so will lose a lot of information for long sequences and cause bad results, so the @bahdanau2014neural then improved the performance by the attention mechanism, where each word in $Y$ is conditioned on different context vector $c,$ with the observation that each word in $Y$ may relate to different parts in $x$. In particular, $y_i$ corresponds to a context vector $c_i$, and $c_i$ is a weighted average of the encoder hidden states $h_1, \cdots, h_T$
Transformer
The Transformer was proposed in the paper Attention is All You Need Transformers is a pioneering work. Many transformer based work, such as GPT, Bert, GPT2, have made significant breakthroughs. The below image is a superb illustration of Transformer’s architecture.

The Encoder is on the left and the Decoder is on the right. Both Encoder and Decoder are composed of modules that can be stacked on top of each other multiple times, which is described by Nx in the figure. We see that the modules consist mainly of Multi-Head Attention and Feed Forward layers. The inputs and outputs (target sentences) are first embedded into an n-dimensional space since we cannot use strings directly. One slight but important part of the model is the positional encoding of the different words. Since we have no recurrent networks that can remember how sequences are fed into a model, we need to somehow give every word/part in our sequence a relative position since a sequence depends on the order of its elements. These positions are added to the embedded representation (n-dimensional vector) of each word.@Transformer_web And these Multi-Head Attention bricks in the model are as followed:

Implementation
In this part, we use pytorch to implement seq2seq and Transformer as the baseline for comparison.


By using pytorch, we can easily build Seq2Seq and Transformer model. Before training, we use the ’GoogleNews-vectors-negative300.bin.gz’ word2vec pre-train dataset as the first Embedding look up layer.
It should be noted that vanilla Transformer is very hard to obtain the good performance on these datasets. In order to make sure the stable performance, i leverage the multi-head self-attention (1 layer, you can change it) on the RNN-based Seq2Seq-attn, which shows the better performance.
Because the model is base on GRU, so it takes long time to train. And the loss can be see followed by tensorborad recorder:
,Transformer(Blue)")
As we can see, for seq2seq, although the loss of dev test set is gradually gentle, but the loss of training set is still declining, which shows that epoch = 50 is still too little, training more epoch can get better performance. But for Transformer model, when epoch is 20, the dev test dataset get the lowest then become higher, which means it’s
overfitting after 20 epochs.
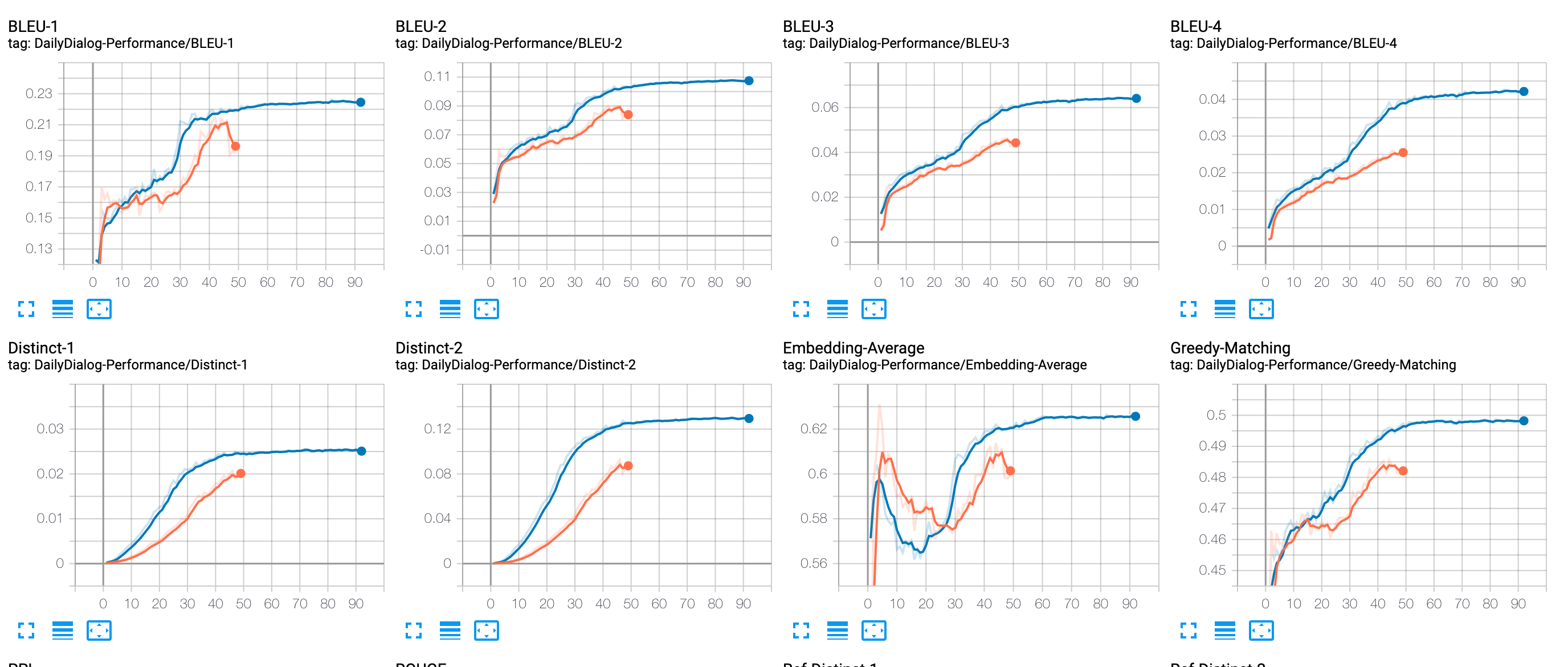
From the graph of metric, it can be seen that Transformer performance absolutely better than Seq2Seq. Though we train more epoch on Transformer, but it always get a higher performance than Seq2Seq model with the same epoch. The final result as followed table:
| Model | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | InterDist-1 | InterDist-2|
| -------------------| --------| --------| -------- |--------| ------------- |-------------|
|Seq2Seq+Attention | 0.1931| 0.0826 | 0.0491 | 0.0256 | 0.0204 | 0.0898|
| Transformer | 0.2253 | 0.1079 | 0.0644 | 0.0424 | 0.0255 | 0.1295|
Plato
Baidu announced the PLATO pre-training model for general domain dialogues in October last year, and related papers@bao2019plato have recently been officially accepted by ACL 2020. Specifically, PLATO is the first end-to-end pre-trained dialogue generation model based on latent space. So it uses hidden vectors to represent the potential direction of the conversation. Because of that, it successfully get a pretty significant increase in the fluency of the conversation. For specific dialogue tasks, PLATO can be used to train a very smooth dialogue system with a small amount of data as well.
Model Introduction
In the model of Plato, there are three different elements, respectively dialogue context c, response r and latent variable z. The most notable element is the latent variable. In PLATO, discrete latent variables can have K values, each of which is corresponding to the intention in a reply, or can be understood as a variety of dialogue actions, we call this intention ‘Latent speech act’.
In PLATO training, there are 2 tasks which will be worked simultaneously, they will share network parameters as well. Respectively response generation and latent act recognition. Therefore if the the context and discrete latent variables are given (that is, determining the intent in the reply), then generation task will maximize the likelihood probability of the target reply, which use the formula as:
$$p(r|c,z) = \prod_{t=1}^Tp(r_t|c,z,r<t)$$
At the same time, the recognition task tries to estimate the value of the hidden variable corresponding to the target reply and the given context. It is obvious for us to see that, the accurate identification of hidden variables can further improve the quality of reply generation. So we could say that this hidden variable occupies a pivotal position in the Plato model.
Then let us consider the input of Plato model.

From figure 4 we could see that, the input embedding of each token is obtained by adding the corresponding token, role, turn and position embedding. To make sense, in token embedding, except the normal ones, E$_{[z]}$ is mapped from the latent embedding space. And E$_{[EOU]}$ and E$_{[BOU]}$ represent end-of-utterance token, begin-of-utterance token. Role embedding contains the information of which character is talking. As there would be multiple turns in one dialogue, the turn embeddings are responsible for record the order of turns for all the utterance. Position embeddings are added to record the position of each token in an utterance.
Below is figure 5, which is the pre-trained network architecture with discrete hidden variable dialogue generation.

As we mentioned before, during the pre-training, two tasks were carried out synchronously: Response Generation and Latent Act Recognition.
In the response generation task, PLATO borrowed from UniLM to use a flexible attention mechanism. Hence just like the UniLM, in Plato model the context was bidirectionally encoded to make full use of the information in context, then it could get better understanding on our dataset; on the other hand, it unidirectionally decoded the response to adapt to the auto-regressive feature of response generation.
In the hidden variable recognition task, PLATO uses the special symbol [M] as input to collect the information given above and the target reply, which is used to estimate the response intention (i.e. the value of the discrete hidden variable).
Finally, in the PLATO model training process, it uses three loss functions: negative log-likelihood (NLL) loss, bag-of-words (BOW) loss and response selection (RS) loss. Among them, NLL loss is commonly used in text generation task as you know. As for the BOW loss, PLATO introduced this function to facilitate the training of discrete latent variables. In addition, RS loss can help determine the relevance of a reply to the above. From these three functions talked above, it is simple to calculate the total loss which is the sum of the results of these three loss function.
Implementation

Because the training of dialogue generation model need high-performance GPU, we train the models on the Google Colab platform with 16G Nvidia Tesla P100 and 24G RAM. Before training the model, we need to preprocess the corpus into Bert.jsonl form and we run these two pre-trained dialogue generation model provided by PLATO on the dialogue data:
- PLATO, uncased model: 12-layers, 768-hidden, 12-heads, 132M parameters
- PLATO w/o latent, uncased model: 12-layers 768-hidden, 12-heads, 109M parameters
To accelerate the training process, we set the learning rate to $5e-5$. Although the official experiment recommend 2-3 epochs, we set the training epochs to 6 to ensure that the models can converge, which makes model perform well in the dialogue task. During the process, we use VisualDL to visualize the training loss, NLL and token NLL which is shown in Figure.

We can see that the curve deceases like steps because the model is trained step by step. In other words, the model reaches convergence at each epoch using the subset of the whole training data. However, by analyzing the curve on training set (blue curve) and validation set (red curve), we can find at each epoch, the curve drops sharply during the beginning of the epoch and rises slowly after reaching the lowest points.
The performance of the dialogue generation model is evaluated by BLUE-1/2 and Dist-1/2 on the testing dataset. We just set parameter do_infer = true, the PLATO will automatically generate the response for the dialogue testing corpus and compute BLEU and Dist. We run these two models, 109M baseline model and 132M model, on the DailyDialog dataset and the detailed results are shown in Table.
| Model | BLEU-1 | BLEU-2 | IntraDist-1 | IntraDist-2 | InterDist-1 | InterDist-2|
|--------------------- |--------| -------- |-------------| ------------- |-------------| -------------|
| 109M Baseline Model | 0.399 | 0.316 | 0.927 | 0.979 | 0.040 | 0.209|
| 132M Model | 0.486 | 0.389 | 0.882 | 0.972 | 0.033 | 0.189|

We can see that with the same training epochs 6, the 132M-parameters models performs better than baseline model with higher BLEU-1/2 scores. However, it also need more time to train for each epoch. The total training time of the 132M model is about 8 hours, compared with 6 hours of the 109M baseline model.
Application: A Demo Chatting Robot
We build a web project to implement a chat box with the well trained PLATO Model. The framework of this project is based on flask and we create an Model API that is able to predict an answer generated from the input question. Below graph shows a demonstration of the web project. From the graph we can find that the PLATO model can smartly react some basic sentences which is close to the normal conversation. Furthermore, the context relationship between successive conversations can be captured to some extend. However, an drawback of this model is that it is easy to be influenced by the context and get caught in the loop that keeping reply the same sentence. One possible reason is that the data set size is not big enough and it contains insufficient topics. To fix this in the web project, we keep only the last three sentences as input to generate the reply.

Conclusion
The automatic evaluation results of BLEU and Distinct of all the model we used in this project is show in the table 3. From the table we can know that PLATO can get the best results on Daily Dialog dataset which is exactly what we expected.
| Model | BLEU-1 | BLEU-2 | InterDist-1 | InterDist-2 |
|---|---|---|---|---|
| Seq2Seq+Attention | 0.1931 | 0.0826 | 0.0204 | 0.0898 |
| Transformer | 0.2253 | 0.1079 | 0.0255 | 0.1295 |
| Plato | 0.486 | 0.389 | 0.033 | 0.189 |
本博客文章除特别声明外,均可自由转载与引用,转载请标注原文出处:http://www.yelbee.top/index.php/archives/183/

){kind=link}
){kind=link}